EEG-Inception:一种基于ERP辅助脑机接口的深度卷积神经网络
简介
本文的研究提出了一种新的卷积神经网络(CNN):EEG-Inception,可以改进基于ERP的脑机接口的精度和校准时间。
模型在73名被试上进行验证,其中31%的被试存在运动障碍。实验结果表明提出的EEG-Inception模型优于所对比的5个方法(rLDA、xDAWN+黎曼几何、CNN-BLSTM、DeepConvNet和EEGNet),分别实现提高了16.0%, 10.7%, 7.2%, 5.7% 和5.1% 的解码性能。
EEG-Inception通过跨被试迁移和fine-tuning的方式,可以实现需要非常少的校准试次可实现SOTA的性能,对实际应用而言有更好的灵活性。
方法
数据预处理
- 首先降采样到128 Hz;
- 采用通带为0.5-45 Hz的带通滤波器;
- 采用CAR空间滤波器提高了ERPs的信噪比;
- 对数据进行切分,从刺激开始时刻到之后的1000 ms为止。
输入模型的EEG为大小 128采样点×8导联 的数组。
模型框架
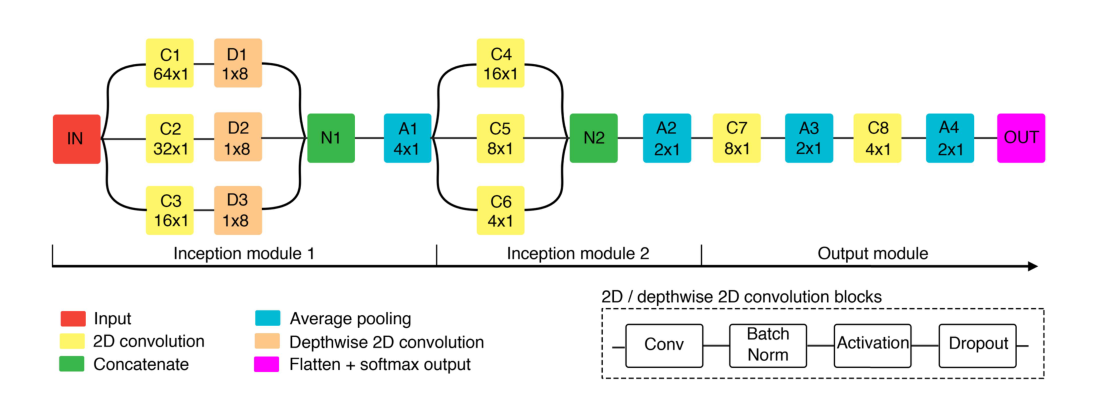
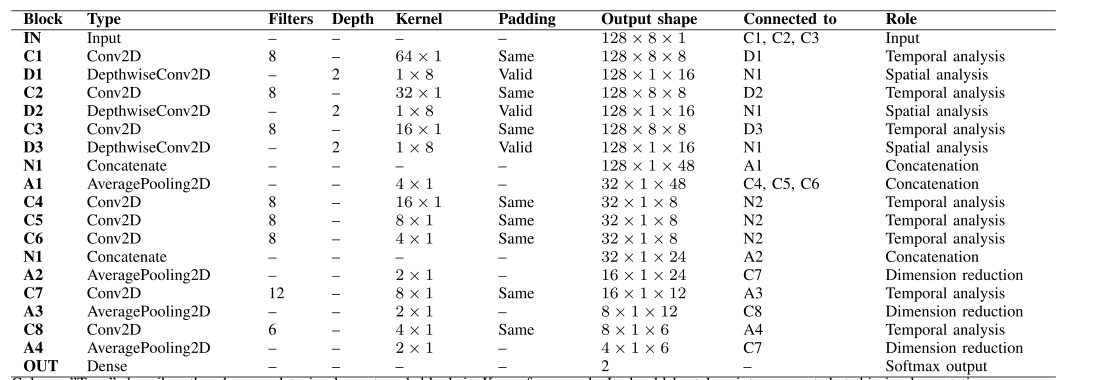
Inception模块1
该模块根据C1、C2和C3卷积块的核大小,分别为64 × 1、32 × 1和16 × 1,在3个不同的时间尺度上处理每个脑通道的信号。因此,由于输入的采样率为128 Hz,这些大小对应的时间窗口分别为500 ms、250 ms和125 ms。
【卷积+深度卷积】*3+串联+池化
 在这些层之后,D1、D2和D3使用深度卷积在空间域处理信号。首先在图像分类域使用深度卷积,通过分别作用于每个输入通道,将一个卷积核分解为更小的核,减少了参数总量,。当应用于脑电图处理时,它们提供了一种方法来学习由前一层提取的每个时间模式的最优空间滤波器(即通道权重)。然后,串联层N1将D1、D2和D3的输出特征进行合并。最后,采用平均池化方法进行降维。
在这些层之后,D1、D2和D3使用深度卷积在空间域处理信号。首先在图像分类域使用深度卷积,通过分别作用于每个输入通道,将一个卷积核分解为更小的核,减少了参数总量,。当应用于脑电图处理时,它们提供了一种方法来学习由前一层提取的每个时间模式的最优空间滤波器(即通道权重)。然后,串联层N1将D1、D2和D3的输出特征进行合并。最后,采用平均池化方法进行降维。
Inception模块2
这个模块和前一个模块一样组织。它由3个分支组成,分别对500 ms、250 ms和125 ms 3个时间尺度的脑电信号进行处理。
【卷积】*3+串联+池化
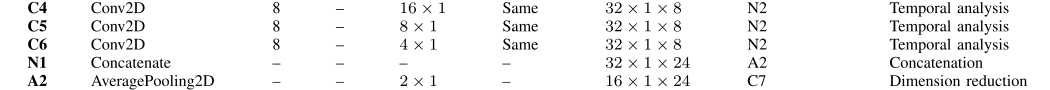
需要注意的是,在第一个块的平均池化层之后,这些尺度对应的内核大小分别为16 × 1,8 × 1和nd 4 × 1。该模块在更高的抽象层次上提取额外的时间特征,考虑到所有的脑电通道。如前所述,卷积块C4、C5和C6的输出被串联起来。然后,采用平均池化降维。
【卷积+池化】*2+分类
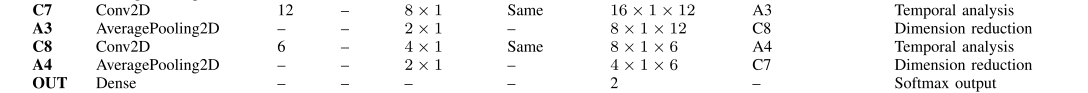 最后2个卷积层用于提取最有意义的模式用于最终的分类,将信息压缩成少量的特征。值得注意的是,过滤器的数量逐渐减少,这与
最后2个卷积层用于提取最有意义的模式用于最终的分类,将信息压缩成少量的特征。值得注意的是,过滤器的数量逐渐减少,这与平均池化层一起降低了维数,以避免过拟合。事实上,最终的分类层只提供了24个特征。最后,softmax输出估计每个类(目标和非目标)的概率。
训练
模型使用以下配置进行训练:
Adam优化器- 默认超参数β1 = 0.9 和 β2 = 0.999
交叉熵损失函数- 500轮训练。
- 为了加速训练和避免过拟合,当验证集的损失连续10个epoch没有改善时,应尽早停止,恢复最小化该指标的权值。
对比方案
正则化LDA (Regularized LDA, rLDA)
|简介|基于收缩估计的LDA的正则化版本| |–|–| |方法{rowspan=3}|预处理阶段采用0.5 ~ 10Hz的带通滤波和CAR。| ||然后,在刺激开始后0 ~ 1000 ms提取epoch,并抽取到20hz。| ||将脑电通道拼接,排列出最终的特征向量,并将其输入rLDA进行分类。| |效果|由于其简单和性能被广泛用于ERP检测,优于其他基于LDA的方法,如逐步LDA (SWLDA)。|
xDAWN + RG
|简介|基于RG的具有强鲁棒性和迁移学习能力的模型| |–|–| |方法{rowspan=2}|将xDAWN空间滤波和RG相结合,估计协方差矩阵并将其投影到切线空间| ||然后使用逻辑回归分类器实现鲁棒的ERP分类| |效果|赢得"2015年BCI挑战赛"的算法|
CNN-BLSTM
| 网络结构 | 结合一维卷积层提取空间特征和2个BLSTM(双向长短时记忆网络)层检测时间模式 |
|---|---|
| 效果 | 2019年ERP分类的IFMBE科学挑战第二名 |
DeepConvNet
作为BCI中EEG解码任务的通用模型,由5个卷积块组成,其中包括最大池化层,其中特殊的第一个块用于处理EEG输入,然后是一个密集的softmax分类层
EEGNET
该网络采用批处理归一化和dropout方法来避免过拟合和平均池化降维。
实验结果
数据集
作者将73名被试分为三部分:训练(training)、验证(validation)和测试(test)。所有健康被试者被分为两组对应训练(80%),验证(20%)。31名运动障碍被试作为测试集。 
网络的超参数在验证集上通过网格搜索获得。方法性能评估的测量采用跨被试训练+fine-tuning的模式,具体如下图  在训练集上完成模型训练后,对于测试被试,随机抽取N个trial的脑电数据,对模型进行fine-tuning,在测试被试剩余的数据上进行测试获得最后的精度。
在训练集上完成模型训练后,对于测试被试,随机抽取N个trial的脑电数据,对模型进行fine-tuning,在测试被试剩余的数据上进行测试获得最后的精度。
精度对比
EEG-Inception的准确率一直是最高的,其次是EEGNet、DeepConvNet、CNN-BLSTM、xDAWN+RG和rLDA。事实上,EEG-Inception和其他模型之间的比较显示,rLDA提高了16.0%,xDAWN + RG提高了10.7%,CNN-BLSTM提高了7.2%,DeepConvNet提高了5.7%,EEGNet提高了5.1%。
无论模型如何,序列的数量越多,准确度越高,而且选择的时间也会增加。如前所述,在实际应用中,必须在精度和速度之间取得适当的平衡。在这方面,EEG-Inception可以提供更高的准确性和更少的选择时间。