CNN-SAE
简介
本研究旨在利用深度学习方法提高脑电信号的分类性能。在本研究中,我们研究卷积神经网络(CNN)和堆叠自编码器(SAE)来分类EEG运动想象信号。引入一种新的输入形式,将脑电信号中提取的时间、频率和位置信息结合起来,并将其用于具有一维卷积层和最大池化层的CNN。我们还结合CNN和SAE提出了一种新的深度网络。在该网络中,CNN中提取的特征通过深度网络SAE进行分类。 该方法在BCI竞争IV数据集2b上的kappa值为0.547。比竞赛的冠军算法提高了9%。
创新
- 采用
短时傅里叶变换(STFT)方法将脑电信号时间序列转换为二维图像作为新输入方式。 - CNN对激活模式的时间位置具有部分不变性。
- 利用具有6个隐藏层的堆叠式自动编码器(SAE),通过深度网络改进分类。
数据集
BCI Competition IV数据集2b 在每一组400次试验中,随机抽取90%的试验作为训练集,其余10%作为训练集
网络结构
输入的预处理
对每2s的时间序列进行短时间傅里叶变换(STFT)。在250Hz信号的情况下,这对应于500个样本。进行STFT时,窗口大小为64,时间间隔为14。从样本1到样本500,STFT对498个样本中的32个窗口进行计算,最后剩下的2个样本被忽略。这就得到了一幅257 × 32的图像,其中257和32分别是沿频率轴和时间轴的样本数。 输出频谱的Beta频段。6-13和17-30之间的频带被认为代表mu和beta波段。 
mu波段提取的图像大小为16 × 32, beta波段提取的图像大小为23 × 32。为了保持两个波段的效果相似,采用三次插值方法将beta波段的大小调整为15 × 32。然后将这些图像合并,得到Nfr × Nt图像,其中Nfr = 31, Nt = 32。 对Nc = 3个电极(C4、Cz和C3)重复此过程。结果以一种保留电极邻近信息的方式组合在一起。输入图像的大小为Nh × Nt,其中Nh = Nc * Nfr = 93。
CNN
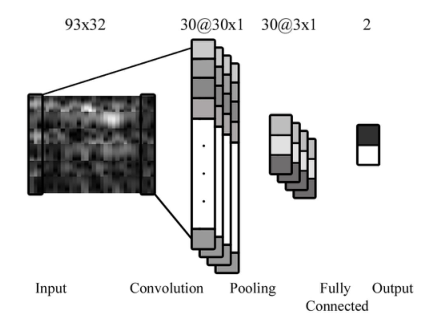 ReLU由softplus函数逼近,定义为 \(\operatorname{RELU}(a)=\ln (1+e^a)\) 它有一个卷积层和一个max-pooling层。网络采用批量训练的方法进行训练,每300个epoch的批大小为50。在SAE方法中,将如图1所示的输入图像进行下采样,并将其转化为900 × 1向量,作为SAE网络的输入。
ReLU由softplus函数逼近,定义为 \(\operatorname{RELU}(a)=\ln (1+e^a)\) 它有一个卷积层和一个max-pooling层。网络采用批量训练的方法进行训练,每300个epoch的批大小为50。在SAE方法中,将如图1所示的输入图像进行下采样,并将其转化为900 × 1向量,作为SAE网络的输入。
SAE
AE (autoencoder)是一种由一输入层、一隐藏层和一输出层组成的网络。输出层的神经元数量与输入层的神经元数量相等。在训练过程中,首先将输入x映射到隐藏层产生隐藏输出y,然后将y映射到输出层产生z值。这两个步骤可以写成 \(\operatorname{y}=f(W_yx+b_y)\) \(\operatorname{z}=f(W_zy+b_z)\) \(\operatorname{f}(a)=1/ (1+e^{-a})\) SAE由一个输入层、多个AEs和一个输出层组成。每一层声发射以无监督的方式单独训练,将前一层声发射中隐含层的输出作为深度网络中下一层的输入。在这个无监督的预训练步骤之后,利用监督微调步骤,通过反向传播算法学习整个网络的参数。本研究中使用的SAE网络。该模型由1个输入层、6个隐藏层和1个输出层组成。每一层的节点数显示在图的顶部。 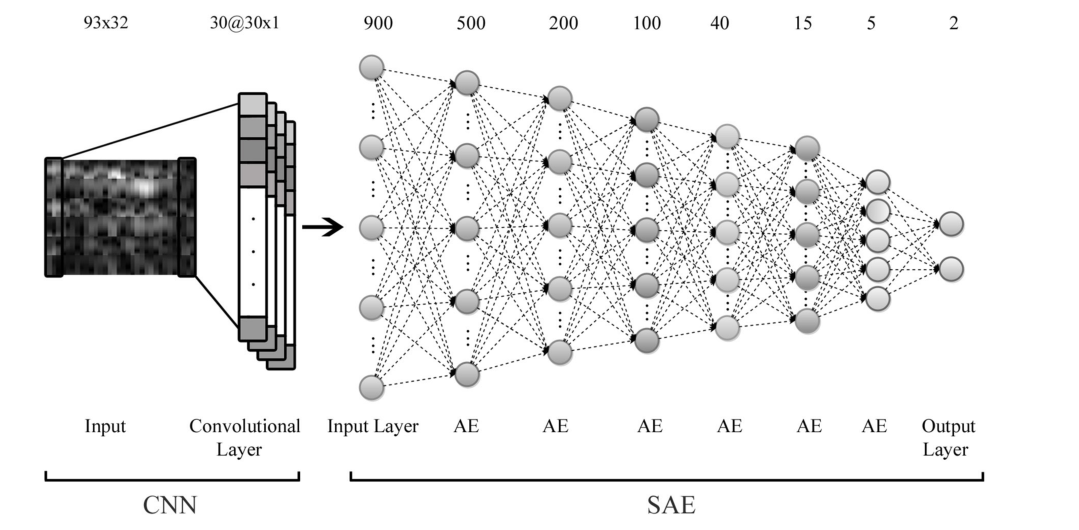
网络连接
将CNN卷积层的输出作为SAE网络的输入。SAE的输入层有900个神经元,它是CNN训练的30个滤波器每个卷积层的30个神经元的输出。利用该模型,我们旨在利用CNN提取脑电数据中考虑时间、频率和位置信息的特征。在SAE部分,我们还通过深度网络来提高分类精度。
结果
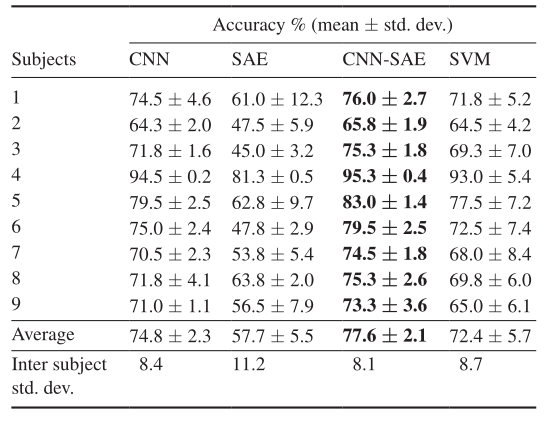 在相同的输入数据下,CNN和CNN- sae方法的平均准确率要高于SVM方法。CNN-SAE方法的受试者间标准差也高于SVM方法。CNN-SAE的平均准确率也高于SAE方法,强调了CNN在提取特征方面的作用。
在相同的输入数据下,CNN和CNN- sae方法的平均准确率要高于SVM方法。CNN-SAE方法的受试者间标准差也高于SVM方法。CNN-SAE的平均准确率也高于SAE方法,强调了CNN在提取特征方面的作用。